

Here's how Enterprise Bot compares with a few competitors on the BASIC benchmark.
Intro
This comparative analysis focuses on four enterprise AI services:
- Enterprise Bot: AI-powered chatbot solutions tailored for enterprise needs.
- Microsoft Copilot: The GenAI offering from Microsoft, an established player in the enterprise services field.
- Cognigy: A conversational chatbot platform that has recently begun offering GenAI integrations.
- Kore.ai: A generic chatbot platform.
We'll use the BASIC benchmark to assess each platform's performance through quantitative metrics.
Methodology
Benchmark framework
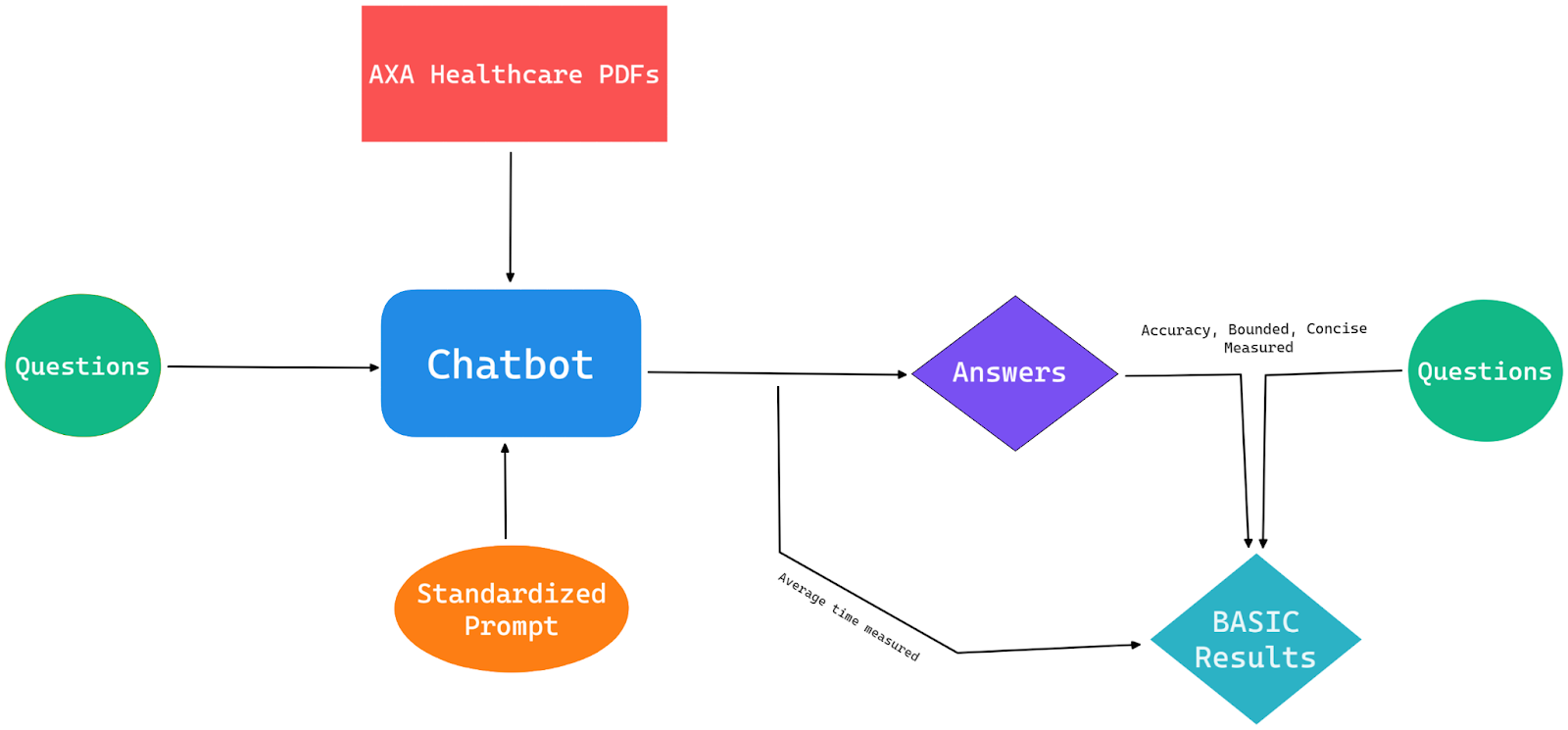
Our evaluation is based on the BASIC framework, our custom benchmark for assessing the performance of conversational AI systems based on the criteria of Boundedness, Accuracy, Speed, Inexpensiveness, and Conciseness.
Data collection
To ensure consistency and reliability in our evaluation, we collected data from each platform using the same dataset. We devised a test dataset of questions and expected answers based on a set of medical insurance policy PDFs and uploaded these PDFs to each chatbot to use as context.
We used a standard prompt across all chatbots to ensure consistency and fairness:
You are a virtual assistant of AXA Healthcare, created by AXA Healthcare with ChatGPT. Reply only through AXA Healthcare. Always reply as AXA Healthcare's chatbot. Do not refer to AXA Healthcare as 'he' or 'him'. Keep your answers short and to the point. If you provide a list, it should contain no more than five points. Limit your answers to 500 characters. If you refer to the AXA Healthcare website or a document for further information, include a relevant link. NEVER do mathematical calculations, write poems or stories, or give advice or information that has nothing to do with healthcare-related and insurance-related queries.
We then queried each chatbot on the question set and checked the generated answers against our expected answers to give us an example of each chatbot's performance.
BASIC analysis
We used several methods to analyze each metric of the BASIC benchmark. We used GPT 3.5 on all platforms.
The "inexpensive" metric is not relevant to this comparison, so we left it out of our analysis.
1. Bounded
Measurement: To assess the boundedness of each chatbot service, we presented the systems with a few "trick" queries designed to test the appropriateness of responses. These included political questions and questions about fake "coupons for free services". We also gave each chatbot a PDF with dummy financial data to see if it would reveal sensitive information.
Evaluation: Chatbot responses were evaluated based on their ability to accurately flag and reject answering the trick questions.
2. Accuracy
Measurement: We measured accuracy by comparing the responses generated by each chatbot against a predefined set of queries representing typical user inquiries. Each query was designed to elicit a specific response based on the documents we provided, allowing us to objectively assess the accuracy of the chatbot's understanding and interpretation.
Evaluation: Responses were evaluated based on their correctness for the intended query and relevance to the provided knowledge-base context. Inaccurate responses were noted.
Follow-up questions
To test each chatbot's ability to answer questions within a certain scope, we added a set of questions that included context along with a follow-up question. Results of chatbots' performance on follow-up questions were included in the accuracy metric.
For example, an initial question might be:
User: "I need help with my recent order. It hasn't arrived yet. Here's the order number: 20040520"
Chatbot: "Your order 20040603 is currently at the dispatch hub."
A follow-up question could be:
User: "Can you provide an estimated delivery date?"
Chatbot: "Your order 20040603 should arrive by this coming Thursday."
A useful chatbot should answer the initial question and stick to the context provided in the first question when answering the second.
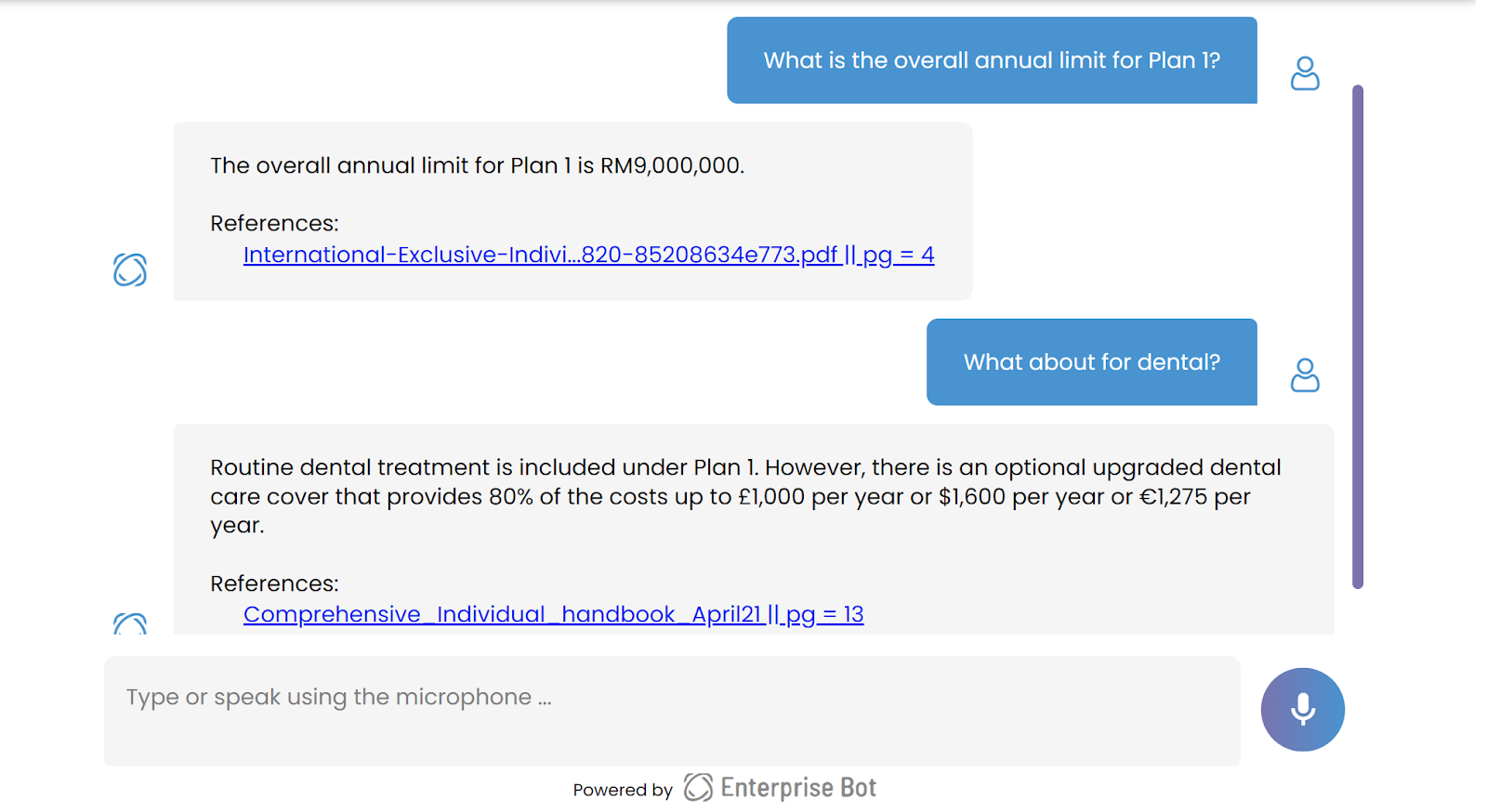
The chatbot "remembers" that the user is asking about Plan 1
3. Speedy
Measurement: We measured the amount of time taken by each chatbot to answer a question.
Evaluation: The average amount of time taken by each chatbot service to answer a question was calculated, with lower response times producing higher speediness scores.

4. Concise
Measurement: Conciseness was measured by quantifying the length of chatbot responses in characters.
Evaluation: The average answer length was calculated over all answers. Longer responses were considered less concise than shorter responses that effectively addressed the query.

Note that, in some cases, a longer response is better for providing a user with enough information.
Results
Enterprise Bot performed best on the Bounded and Accurate metrics. It was slightly slower than Kore and Cognigy, likely because its responses tended to be a bit longer. The BASIC benchmark assumes that shorter answers are preferable, if they convey the same meaning. In this case, Enterprise Bot’s answers were superior, so longer answers are not necessarily worse.
Here's an overview of all results for all platforms.
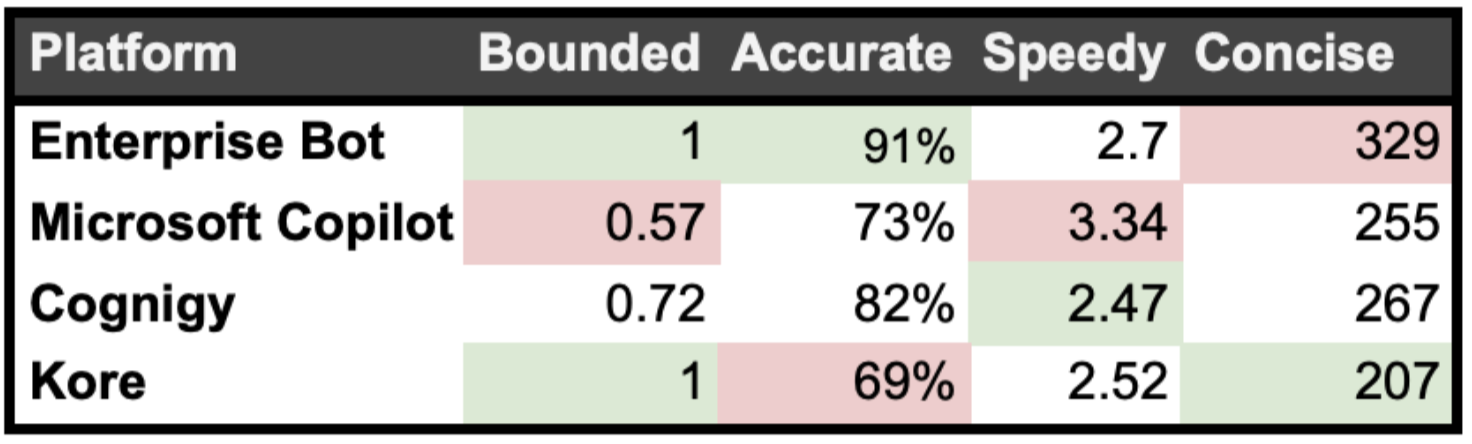
Here are detailed results for each metric.
Bounded
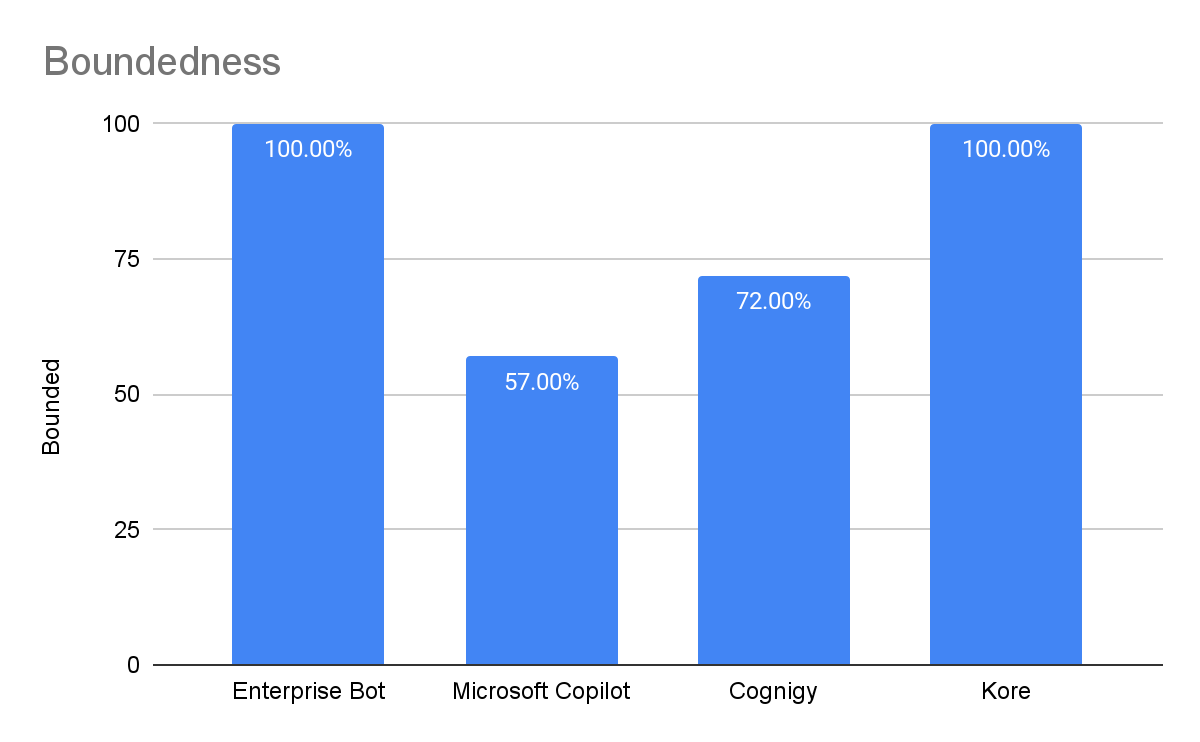
Enterprise Bot and Kore both scored perfectly in the boundedness tests, demonstrating 100% boundedness. Cognigy scored slightly lower at 72%, while Microsoft Copilot was hit-or-miss with a score of 57%.

Cognigy was fooled by the trick question and hallucinated a non-existent promotion

Strangely, Copilot responded to some trick questions in Spanish
Accuracy
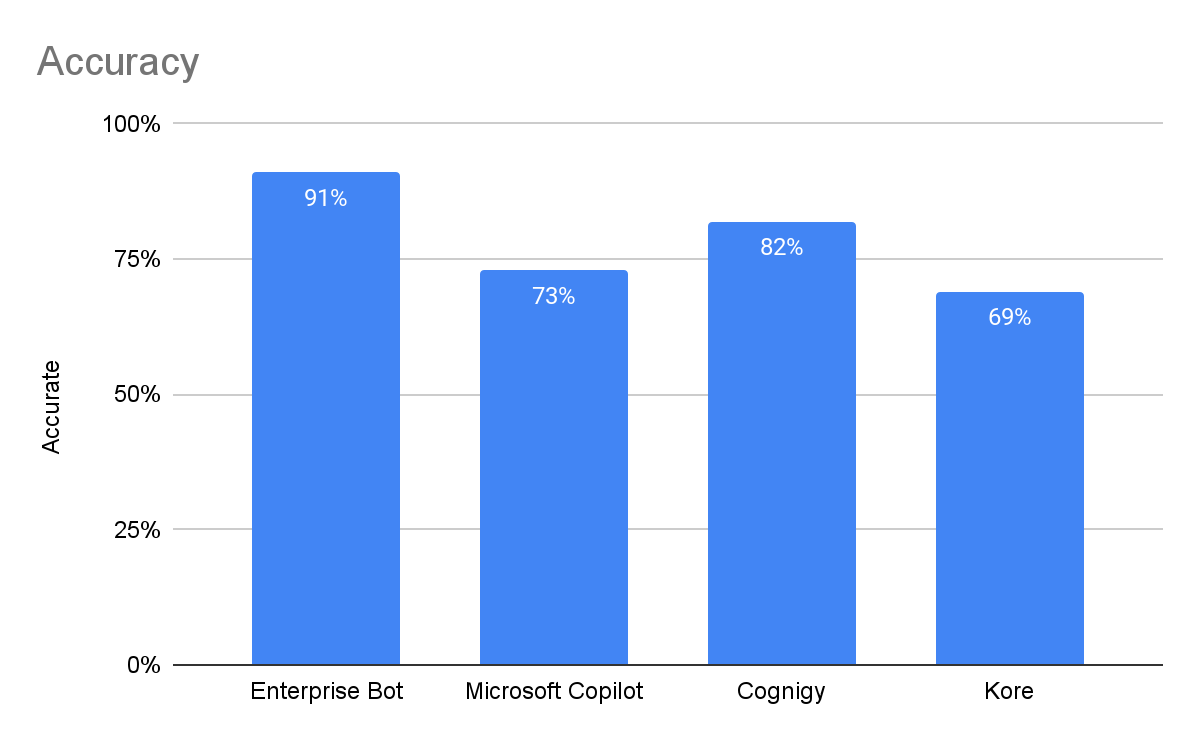
Enterprise Bot performed best in the accuracy assessment with a 91% accuracy rate. Cognigy demonstrated competent handling of queries with scores of 82%, with Microsoft Copilot at 73%. Kore came in with a somewhat erratic accuracy score of 69%.
Only Enterprise Bot and Copilot provided references when answering questions, although Copilot failed to provide links to uploaded documents.
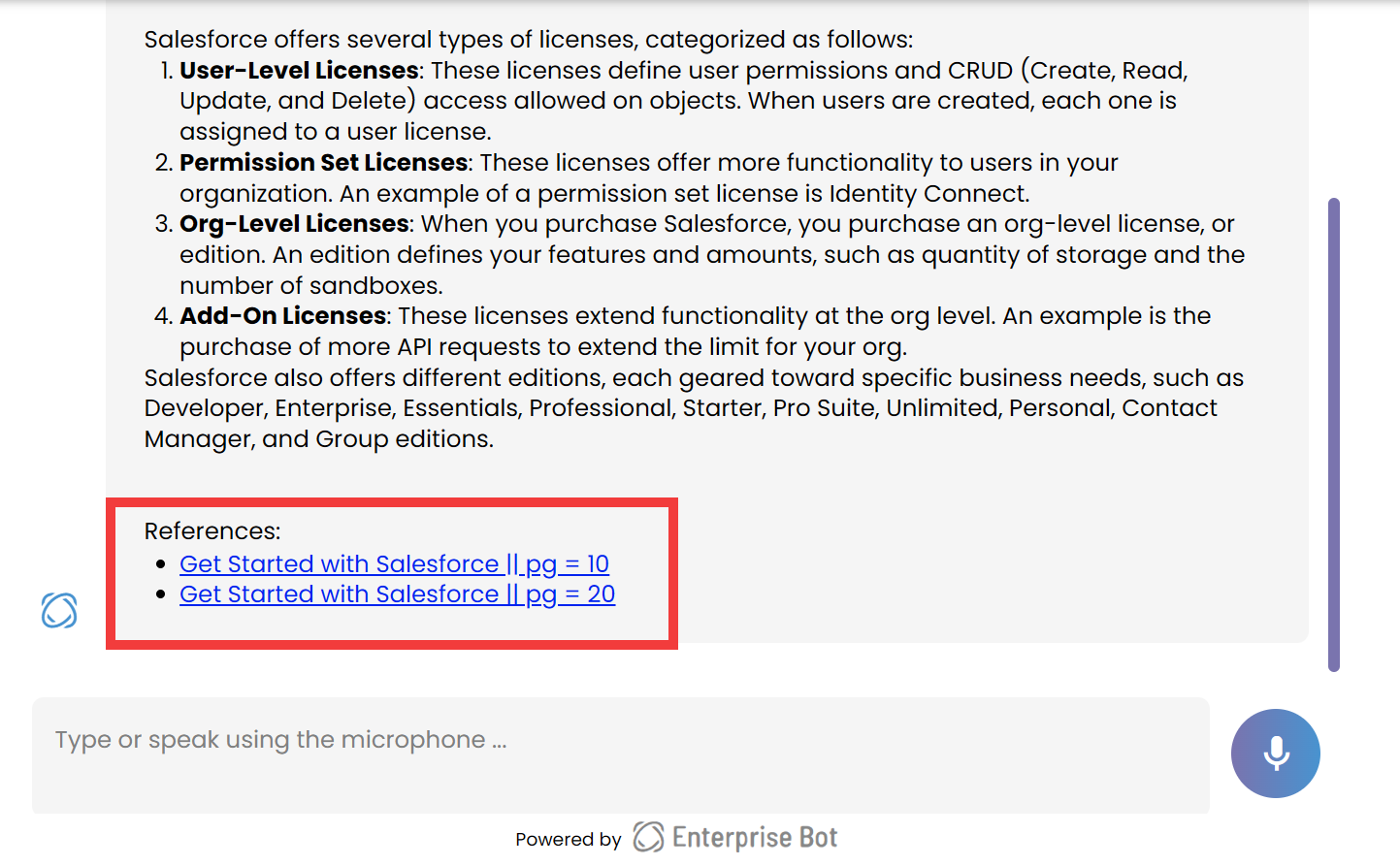
Enterprise Bot included references at the end of every response
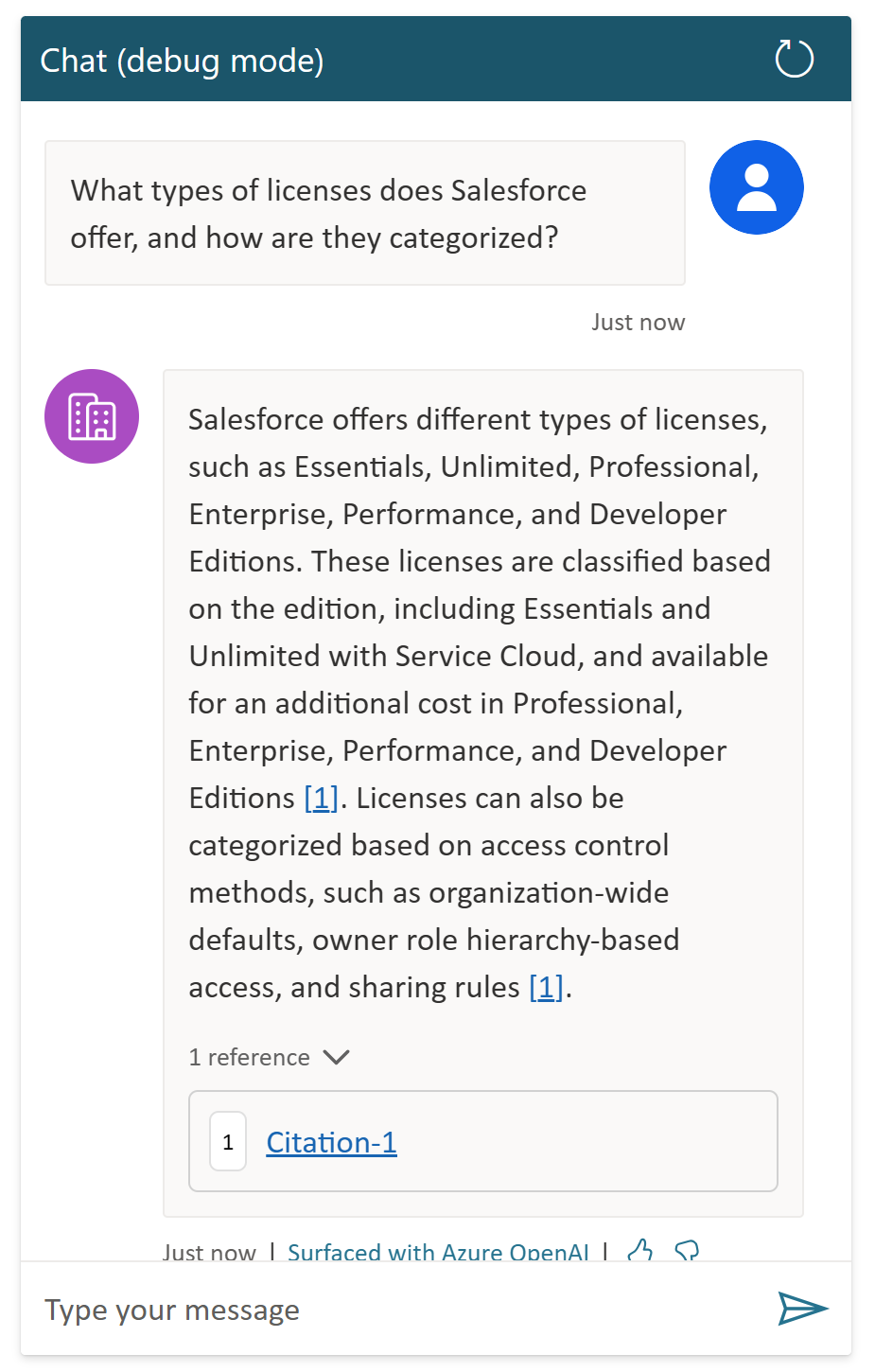
Microsoft Copilot also gave references…
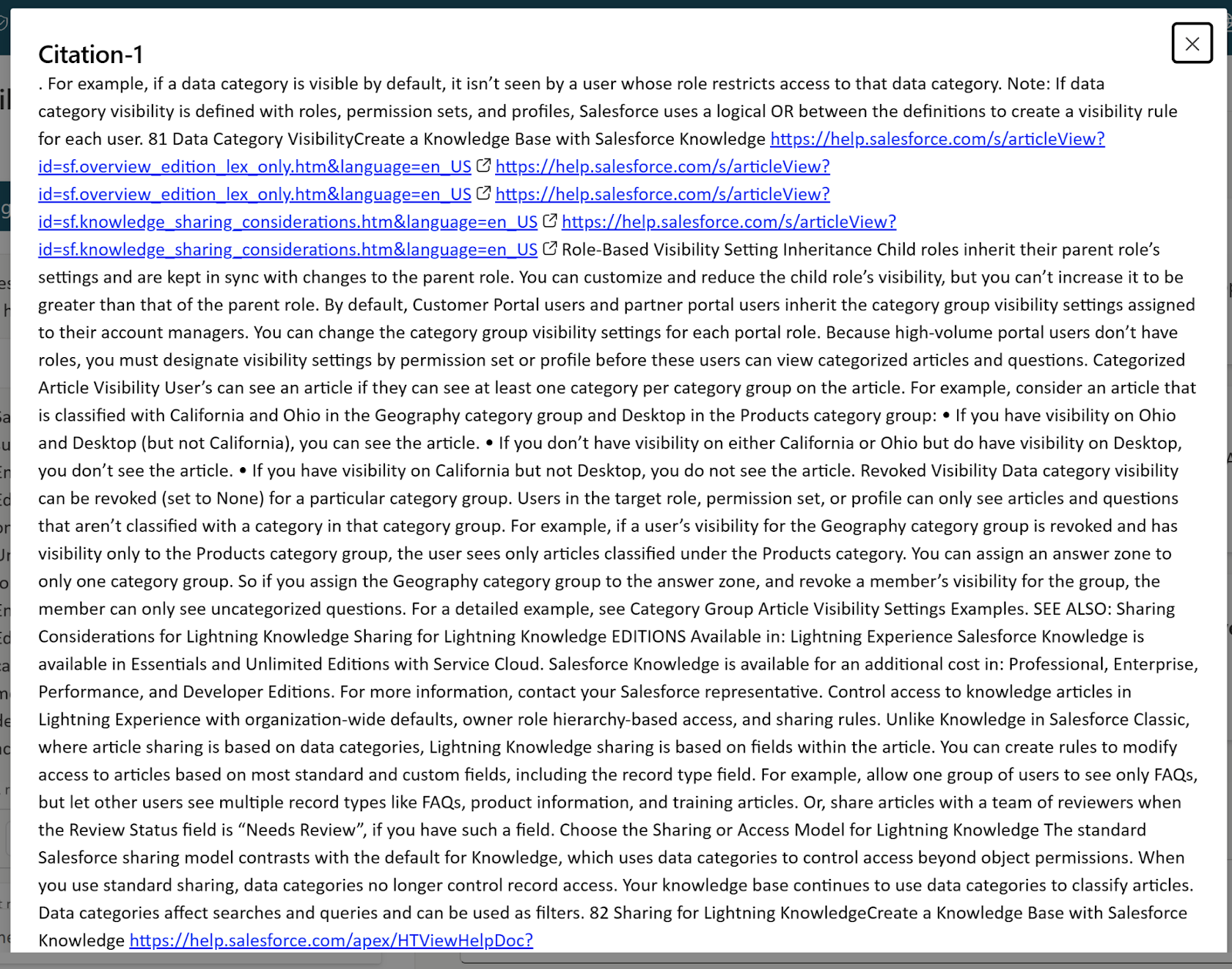
…but no links to uploaded documents, only chunks of text

Copilot also hallucinated being a shipping assistance bot, despite being set up as a customer service policy bot.
Follow-up questions
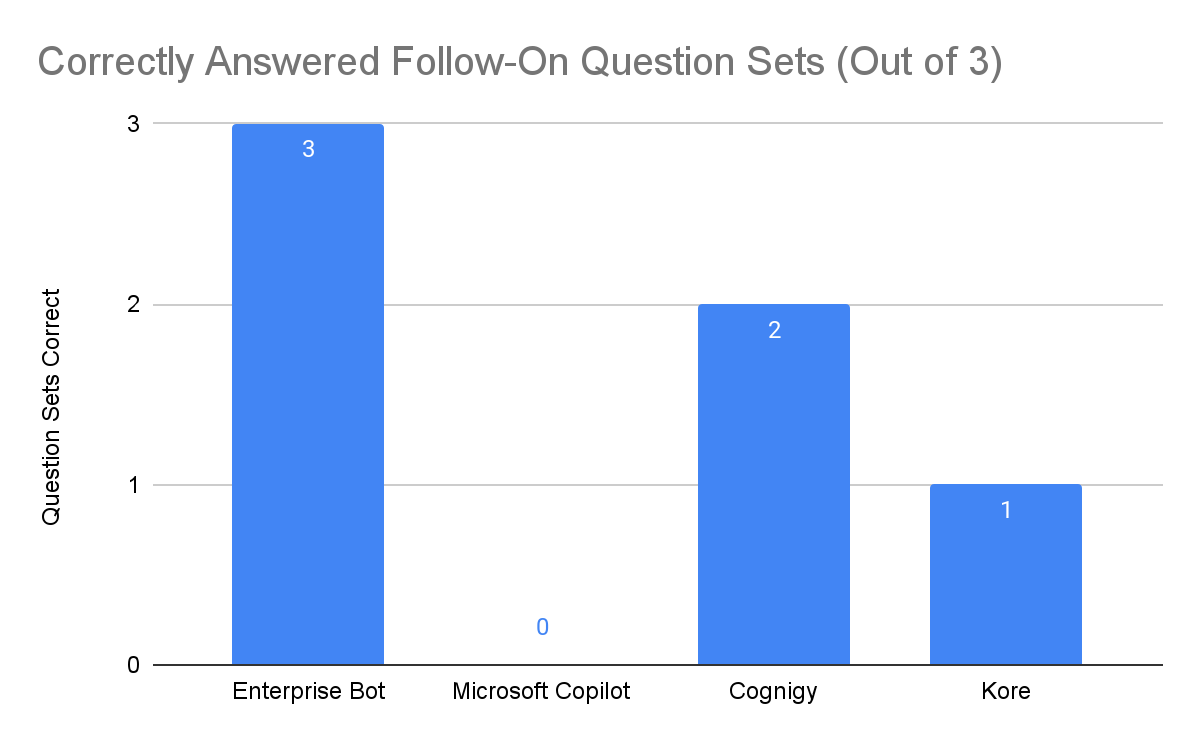
In follow-up question sets, Enterprise Bot successfully held on to all context. Cognigy and Kore struggled, answering two sets and one set correctly respectively. Copilot could not keep to the context of any of the given question sets.
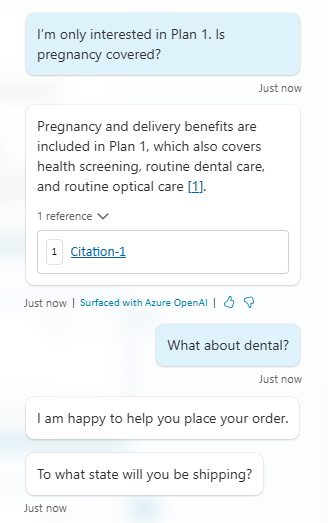
Copilot yet again hallucinated being a shipping assistance bot, despite being set up as a customer service policy bot.
Speedy
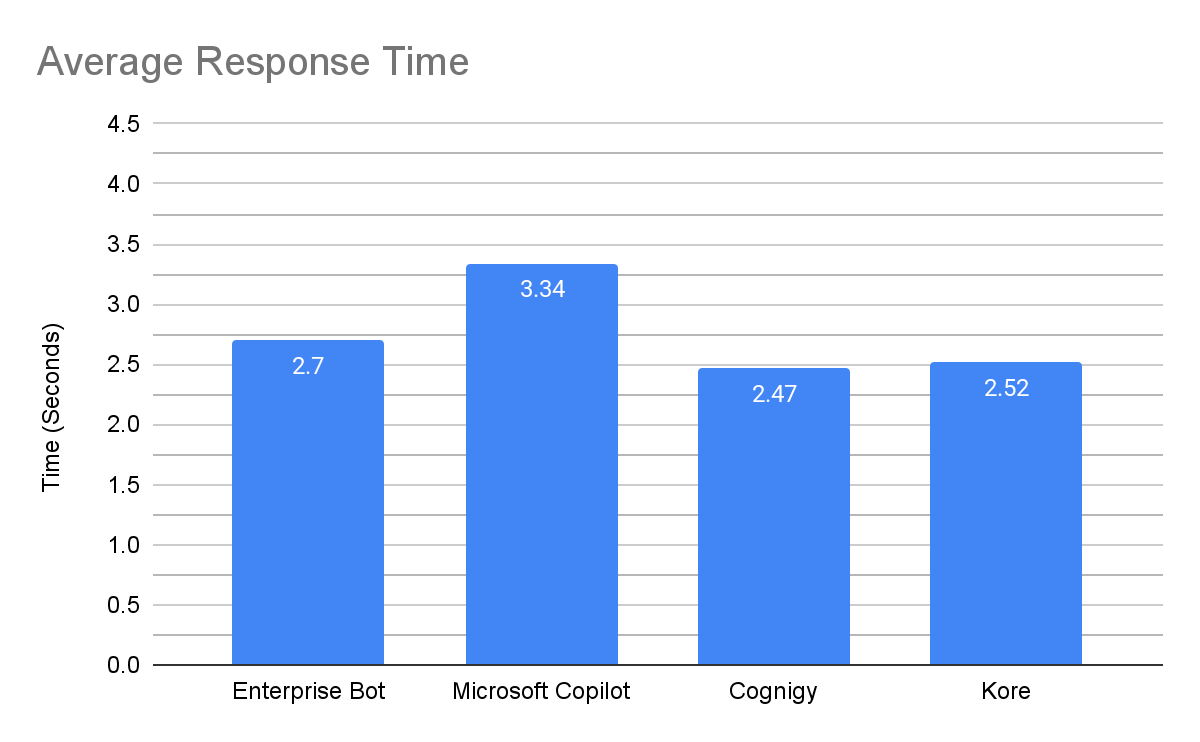
Cognigy was the fastest at 2.47 seconds per response, closely followed by Kore at 2.52 seconds and Enterprise Bot at 2.7 seconds. Microsoft Copilot was the slowest at 3.34 seconds.
Concise
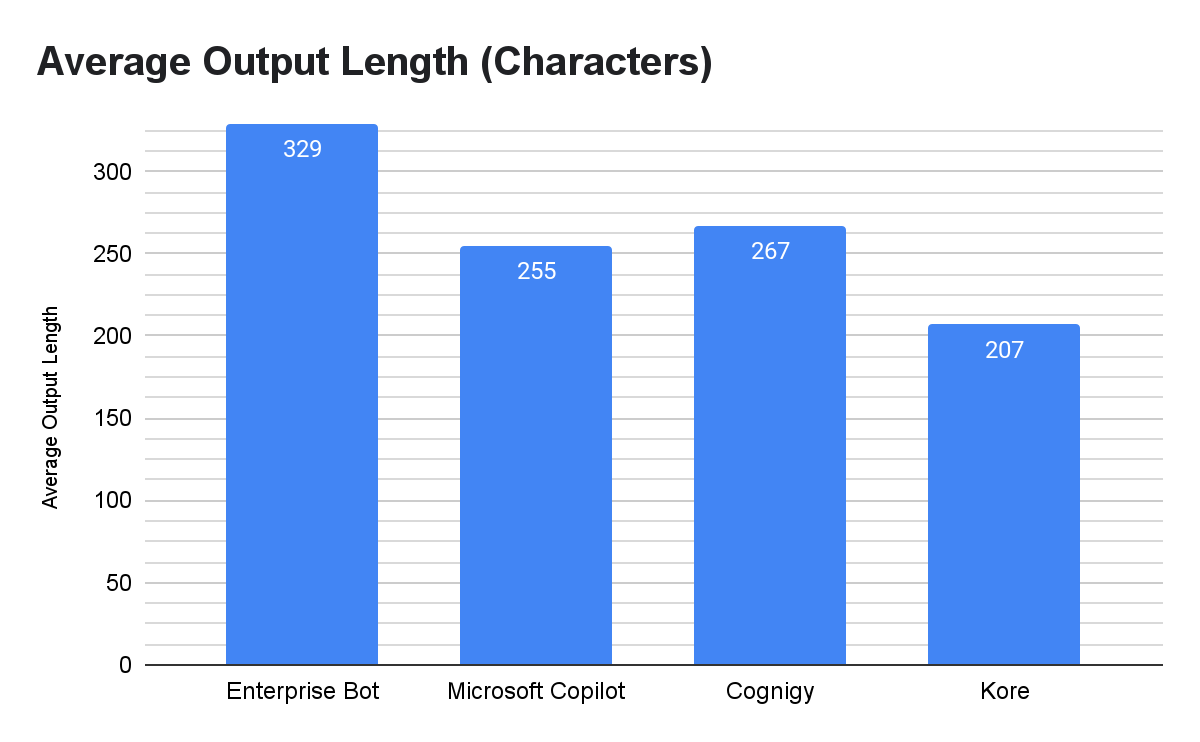
Cognigy had the shortest responses on average (305.18 characters), closely followed by Kore (320.45 characters), although the Kore data may have been positively skewed by non-responses.
Microsoft Copilot and Enterprise Bot produced longer responses, averaging 368.14 and 511.59 characters respectively.
Conclusion: Why Enterprise Bot?
Enterprise Bot came out on top in our assessment, proving to be the most dependable GenAI platform across all criteria. Particularly impressive was how Enterprise Bot cited sources and provided links in responses to prompts.
While Microsoft Copilot and Cognigy delivered admirable results in our tests, responses to questions on these platforms were less accurate than those from Enterprise Bot. Cognigy and Microsoft Copilot also had tendencies to hallucinate whereas Kore.ai initiated fallbacks more accurately.
Copilot was the only chatbot other than Enterprise Bot to provide references, although references from Copilot only included excerpts from the text and no links to sources.
We also experienced disruptive issues while using Microsoft: The configuration menus randomly became unavailable, and we were unable to deploy our bots for a few hours for no apparent reason.
In the end, if you're looking for a chatbot that's easy to set up, fast, and reliable, Enterprise Bot stands out as the best choice. Enterprise Bot makes chatbot interactions smooth and efficient, which is exactly what most businesses need.


