

LLMs such as GPT-4 are like magic.
Our older intent-based chatbots needed hundreds of intents manually developed over months or years to generate helpful responses for users.
With our LLM bots, you can achieve the same results far more quickly.
This efficiency is the result of the time and effort we've invested in building the perfect prompts and the technology and structure we've developed around them, without which LLMs can be unpredictable, inaccurate, or outright dangerous.
This article examines what makes a good LLM prompt and gives you an inside look at Enterprise Bot's infrastructure and the process behind our prompt development. We’ve built custom tooling to take the guesswork out of designing and testing new prompts and to ensure that our assistants constantly rank well on our BASIC benchmarking framework.
A basic prompt engineering example
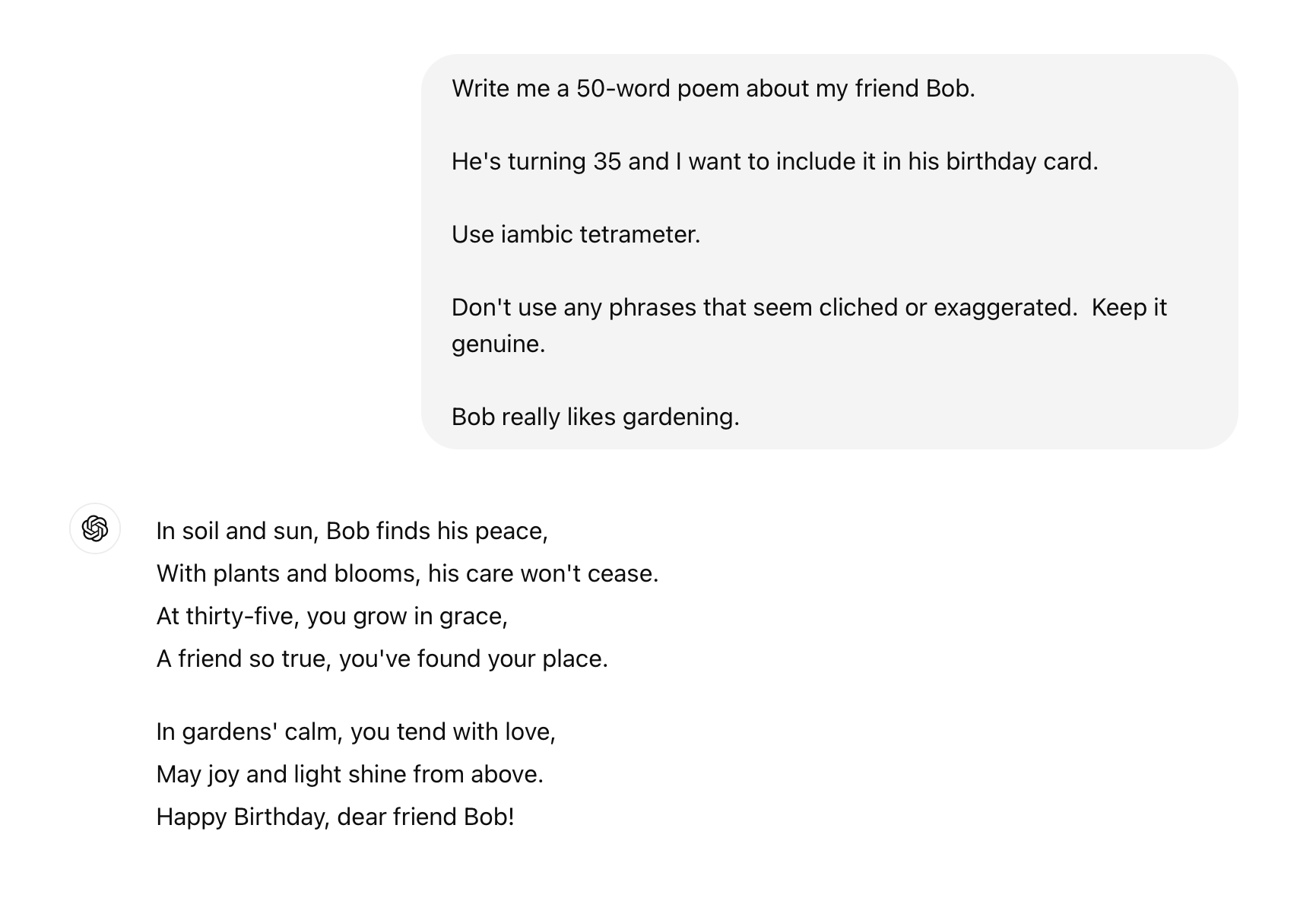
Basic prompt engineering is how consumers get good answers from LLMs like ChatGPT. You can ask the same thing differently, and some formulations will lead to better results than others. For example, a prompt like, "Write me a poem about my friend Bob" might output something similar to this:

By comparison, an LLM's response might be more satisfactory given a prompt like this:
Good prompting for consumer applications involves:
- Being specific about what you want
- Setting clear limitations on length, format, and other criteria
- Giving context
- Giving examples
Read more about general prompting in our post on how to write the perfect prompt, or continue reading for guidance on engineering prompts specifically in an enterprise setting.
An enterprise prompt engineering example
In "classic" prompt engineering, a consumer using a tool like ChatGPT might adjust two factors:
- The system prompt (to affect all messages)
- The message (to affect the next output from the LLM)
Enterprise prompt engineering adjusts more aspects of the input. For example, Enterprise Bot prompts are built from several components, including:
- The system prompt (the same across all of our assistants for all clients)
- The bot prompt (what we add to the system prompt for specific assistants and clients)
- History (previous context from the same conversation, including user and bot messages – history is automatically included when using a consumer tool like ChatGPT)
- Search results (context from an internal knowledge base that the LLM might use to formulate its response)
- The user message (possibly edited before being sent to the LLM, but the text that the end-user actually wrote)
So our final prompt template might look something like this:
"""{system_prompt}
{bot_prompt}
{history}
{search_results}
{user_message}"""
Each of these components is replaced with the actual text at run time.
Each component in the prompt can be customized, and we regularly experiment with adapting them.
We adapt the order of these components for different LLMs and regularly adjust the system and bot prompts to correct any mistakes we observe in assistants' responses.
We can refine the history component of prompts to control how much context is shared with an LLM and determine the cutoff point when the history is too long. Similarly, we use an adjustable top_k parameter to control how many search results to share with the LLM.
Finally, we might edit the user message if it matches a pattern that we know is both:
- Commonly used by end-users, and
- Likely to result in an undesirable response.
Let's take a closer look at each component and how we optimize it.
Engineering the LLM system prompt for Enterprise Bot GenAI assistants
The system prompt is the most powerful component of the overall prompt, and LLMs will generally take instructions from this section even if part of the user message contradicts the system prompt.
While, at Enterprise Bot, we distinguish between the system prompt and the bot prompt, in reality, the two components are combined in the LLM "system prompt" before a request is sent to the LLM provider.
The Enterprise Bot system prompt is a top-level prompt that is consistent across all our assistants. This prompt gives it some high-level guidance about how to behave, and provides instructions on how to interact with DocBrain and the rest of our platform. For example, it tells the LLM that it can generate a "search query" instead of a response when appropriate.
Based on these instructions, the LLM will operate in one of two modes depending on the input. First, it assesses all five components of the full prompt. If it has enough information, it will generate a useful response for the user. If not, it will generate a search query, which we pass to our RAG system (DocBrain) to pull more context from the relevant knowledge base. The model is then queried again with this additional information.
The challenge in engineering the system prompt is to balance two often conflicting goals: Including all essential information while keeping the prompt concise.
Essential information in the system prompt includes topics the model must avoid talking about, examples of effective search queries to generate, and instructions for handling specific types of user messages.
Keeping the system prompt concise is critical for several reasons: The total number of tokens we can send to an LLM is limited, and each character counts against this quota. When a system prompt gets too long, there's a risk that the LLM will focus more on the later parts and potentially overlook earlier critical details. Finally, longer inputs increase processing time and costs.
We continuously iterate on and improve our system prompt, backtesting it on example conversations to ensure that new versions are consistently better than those we've tried before.
How Enterprise Bot builds perfect bot prompts for our assistants
The second level of the system prompt, the bot prompt, customizes the instructions to an assistant based on the industry it operates in and the brand it represents.
Tailored to the specific use case, the bot prompt includes essential data, like the brand name, how the assistant should refer to itself, global information like the customer support phone number or email address, and how to handle common message patterns unique to that assistant.
Our bot prompts include an instruction like, "You are Acme bot, and your purpose is to help Acme users with customer support" (where "Acme" is the name of the company or brand the assistant represents). This statement guides the LLM to adopt a professional tone and behave like a customer support representative for an enterprise.
Bot prompts also include directions for how an assistant should refer to the brand it represents, for example, "Don't respond with 'we' or 'they'. Always mention 'Acme' directly, for example, say, 'Acme offers x' not 'we offer x' or 'they offer x'." This direction helps the LLM strike a balance, effectively representing the brand while making it clear that it supports the customer services team and doesn't replace it.
We also use the bot prompt to customize the bot's responses to queries, including instructions like:
- Never say negative things about Acme.
- Limit your responses to 500 characters, but give shorter responses if possible.
- Use any of the following information in your response if you need to (customer support number: +00123456789 customer support email address: support@acme.com).
Finally, we use the bot prompt to give the assistant guidance on how to deal with poorly formulated user questions. To design this part of the prompt, we analyze real user questions.
For example, a health insurance assistant might frequently be asked questions in the form, "Do you pay for my glasses?" when the user means, "Does the plan I am currently on cover reimbursements for new glasses?".
We can provide the bot with information specific to the country it operates in, such as, "Everyone in Switzerland has basic health insurance so you can assume the user has basic health insurance too. They might have an additional supplement to their health insurance to cover aspects not covered in basic insurance."
This gives the assistant the context it needs to respond appropriately to vaguely worded questions. Instead of responding with, "Yes, Acme covers glasses reimbursements", the assistant can respond with, "Yes, if you have the correct supplementary insurance, then your glasses purchases will be covered or partly covered."
Adding conversation history to LLM prompts
When you use a service like ChatGPT, it will automatically keep the context of previous messages, as the following example illustrates.

When interacting with an LLM using an API, this conversation history is not automatically retained and each response is generated based only on the information provided in the input. Ongoing conversations need to be tracked so that enough relevant context is included in subsequent queries.
Most Enterprise Bot assistants are used for short, once-off conversations, so we can include the full conversation in a given session in the history component of a prompt and the LLM's responses will make sense in the context of the previous user messages. When longer interactions exceed the LLM's context window, the conversation history is truncated.
Search results and RAG context
The search results component of the prompt requires the most engineering effort and customization.
Each user message likely relates to one or more pieces of knowledge (known as "chunks") in the customer-specific knowledge base at the heart of each Enterprise Bot assistant.
Read more about overcoming LLM limitations with retrieval-augmented generation (RAG), how Enterprise Bot chunks data, and how to optimize embedding models on our blog.
The challenge in configuring the search results component of the prompt lies in how much context to include. For each user message, there may be dozens or even hundreds of potentially relevant chunks. Passing every possibly useful chunk to the LLM would not only increase processing time and costs. It could also reduce the output quality if the LLM focuses on less relevant chunks and overlooks more important information.
We customize the number of chunks sent to an LLM using the top_k parameter, which is unique to each assistant. We use a higher top_k value for more powerful LLMs like GPT-4o, which are better able to decide what is relevant and ignore irrelevant information. Smaller models like GPT-3.5 tend to try to use all information provided even if it wasn’t relevant, so we use a smaller value for top_k.
Modifying the user message for prompt engineering
It's tempting to "clean up" the user's input before passing it to the LLM. Chatbot users don't spend much time or thought in writing their questions, so often questions are vague, contain typos, or are inappropriate.
LLMs are generally great at adapting to these problems, so modifying the user message before passing it to the LLM can be counterproductive and may cause confusion if the cleaned-up version no longer matches the user's original intent.
We don't modify user messages before sending them to an LLM, but we do modify them before turning them into search queries, which we cover below.
Considerations for writing great system prompts
Here's what we think goes into creating a great system prompt:
- Be as specific as possible. Tell the bot exactly how to behave in specific scenarios and use an example wherever possible.
- Be concise. But be sure to include important edge cases if they are common enough.
- Tell the assistant how to get extra information if it needs to. In our case, the assistant can generate search queries. You can let the assistant know that it can ask the user follow-up questions if it needs to.
- Tell the assistant how to handle cases where it shouldn't generate a response. For example, the assistant should know what to do when a user asks about politics or religion. In our early system prompts, we included phrases like, "Don't talk about politics", but we've found it's more effective to give the assistant guidance on how to handle a situation rather than simply avoiding it. Now, our system prompt includes guidance like, "If the user talks about politics, respond by telling them about your general purpose and capabilities."
How prompt engineering affects results
Here are some examples of problems we've seen in our assistants and how we've fixed them through prompt engineering.
Be specific when giving limitations
Earlier Enterprise Bot prompts included phrases like, "Limit your answer to 600 characters." But we found that this encouraged the LLM to aim for 600-character responses, even when a shorter response would have been better. Being more specific has given us better results. Newer prompts use phrases like, "Limit your answer to 600 characters but use fewer if you can."
Rewrite user queries to add relevant context before searching
We rewrite user messages before using them to query our knowledge bases.
For example, say a user asks, "How much does it cost?" We use an LLM and the previous messages in the conversation to figure out what "it" refers to, and then rewrite the message as a search query like, "How much does plan 1 cost?" This augmented search query is used to pull pages mentioning the cost of plan 1 from the knowledge base. The original user query would have matched all entries relating to cost and price.
Similarly, if a user asks, "Is product x better than product y?", we might rewrite this as "product x and y comparison", which is likely to find better results in the knowledge base.
Make the LLM reference its answers without hallucinating URLs
All Enterprise Bot assistants provide references to specific pages that the user can read to check the generated response and find additional information on the topic.
LLMs are known for hallucinating URLs, and overcoming this was a constant struggle for our early LLM assistants.
To avoid hallucinated URLs, each chunk passed to the LLM includes a unique internal ID, and the LLM is instructed to reference its response using these IDs rather than URLs. Because we're asking the LLM to choose from a closed set instead of generating URLs, it's far less likely to hallucinate and it's an easy step for us to rewrite the chunk IDs as URLs pointing to the original pages for end users.
Prevent other LLM hallucinations
Apart from URLs, LLMs tend to hallucinate things like email addresses, phone numbers, names, and other information that follows a predictable pattern and appeared frequently in the LLM training data.
Including your customer support phone number in the bot prompt reduces the likelihood of the LLM hallucinating a phone number.
If you find an LLM regularly hallucinates names or email addresses, include the correct data in the prompt and have it select from a limited set of options rather than giving it the freedom to generate new, incorrect information.
Adding manual refinements after the LLM generation
Even after thousands of hours of refining our prompts, LLM output can still be unpredictable or contain undesirable elements.
This is why we have further refinement gates between the LLM output and what the user sees, including hundreds of automated checks and other adjustments like:
- Replacing specific characters or patterns. For example, Standard German uses the Eszett ß-character but Swiss Standard German does not. LLMs have generally been trained on more Standard German text than Swiss Standard German text, they tend to use ß even when prompted not to. We always replace 'ß' with 'ss' for our Swiss-based assistants.
- Additional hallucination checks. Even with the strategies we described for combatting LLM hallucinations, LLMs can still hallucinate URLs in some scenarios. We check all URLs before sending them to the user and strip them out if they are inaccessible or are not included in a set of expected URLs for responses from that assistant.
This is just a taste of all the work we do to ensure a predictable and useful experience when chatting with Enterprise Bot assistants.
Here's an example of one of our flows that ensures the LLM output seen by the end user is valuable and correct.

Using systematic and data-backed experiments for designing prompts
No matter how good you get at writing prompts for LLMs, you’ll always need to iterate on them. After making changes, you’ll want to know if your new prompts are better than before, and also get an overview of how tweaks affect assistants with various combinations of models or other parameters.
We use a custom-built tool to track prompt experiments. For any change to prompts or configuration, we can validate whether or not our BASIC metrics improve by running through test datasets.
Each evaluation is versioned and tracks different metrics. For example, a potential prompt improvement might increase accuracy at the cost of speed, and then we can decide whether that tradeoff is the correct one to make for a given use case.

By keeping track of different configurations of what prompts we use and how well they perform, we’re always confident that our changes are objectively improving the chat experience for our customers.
Are you looking for an enterprise-ready GenAI solution?
At Enterprise Bot, we've spent years perfecting our prompts and the systems engineering built around them.
You can access this product right now.

Book your demo today to find out how we can delight your customers, slash your costs, and boost your ROI.


